High-Intent Bounce
Buyers shortlist with AI before they land. They arrive pre-qualified, with zero patience.
Echo Chamber
Internal reviews loved the page. Real buyers bounce in five seconds.
Engine · 01
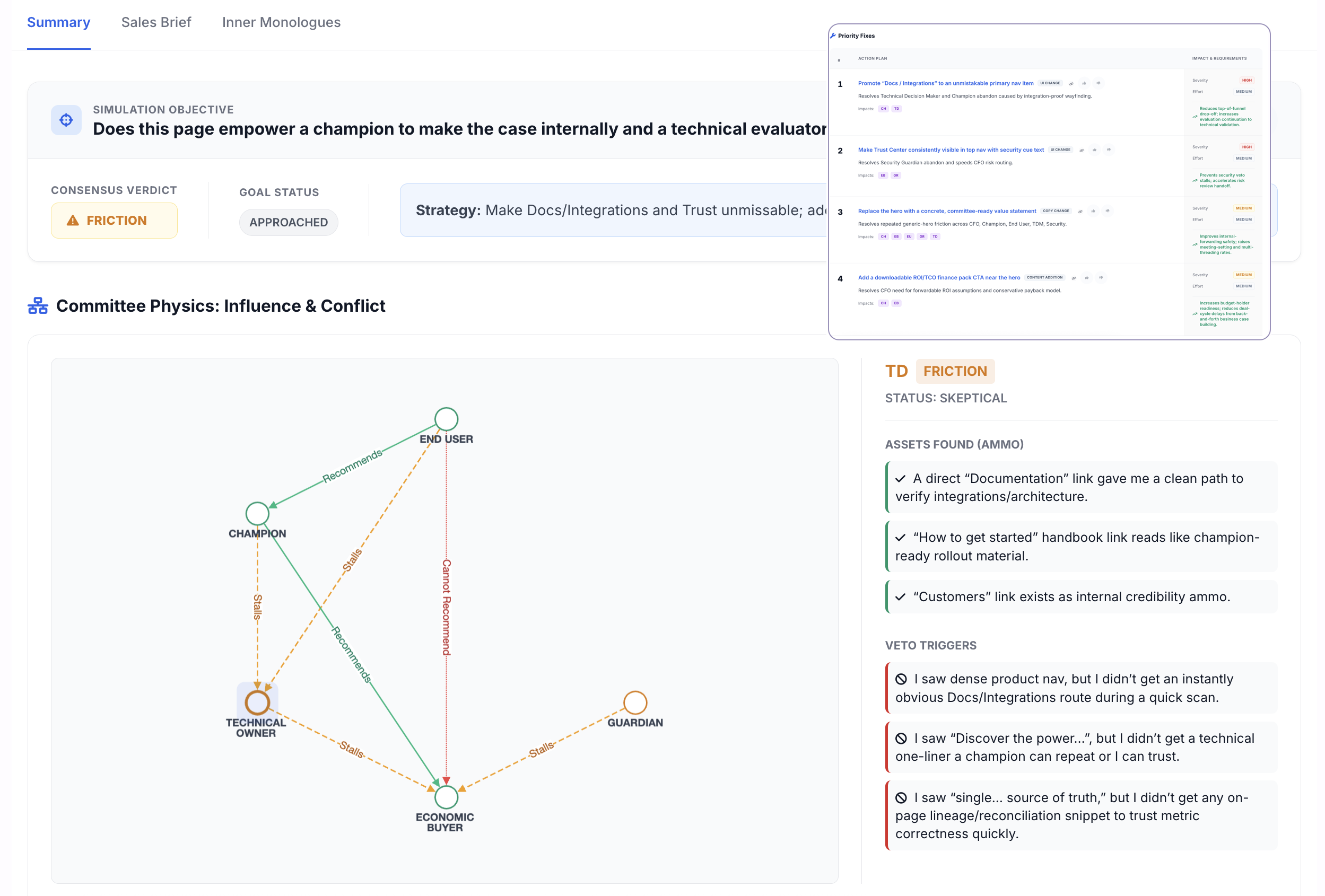
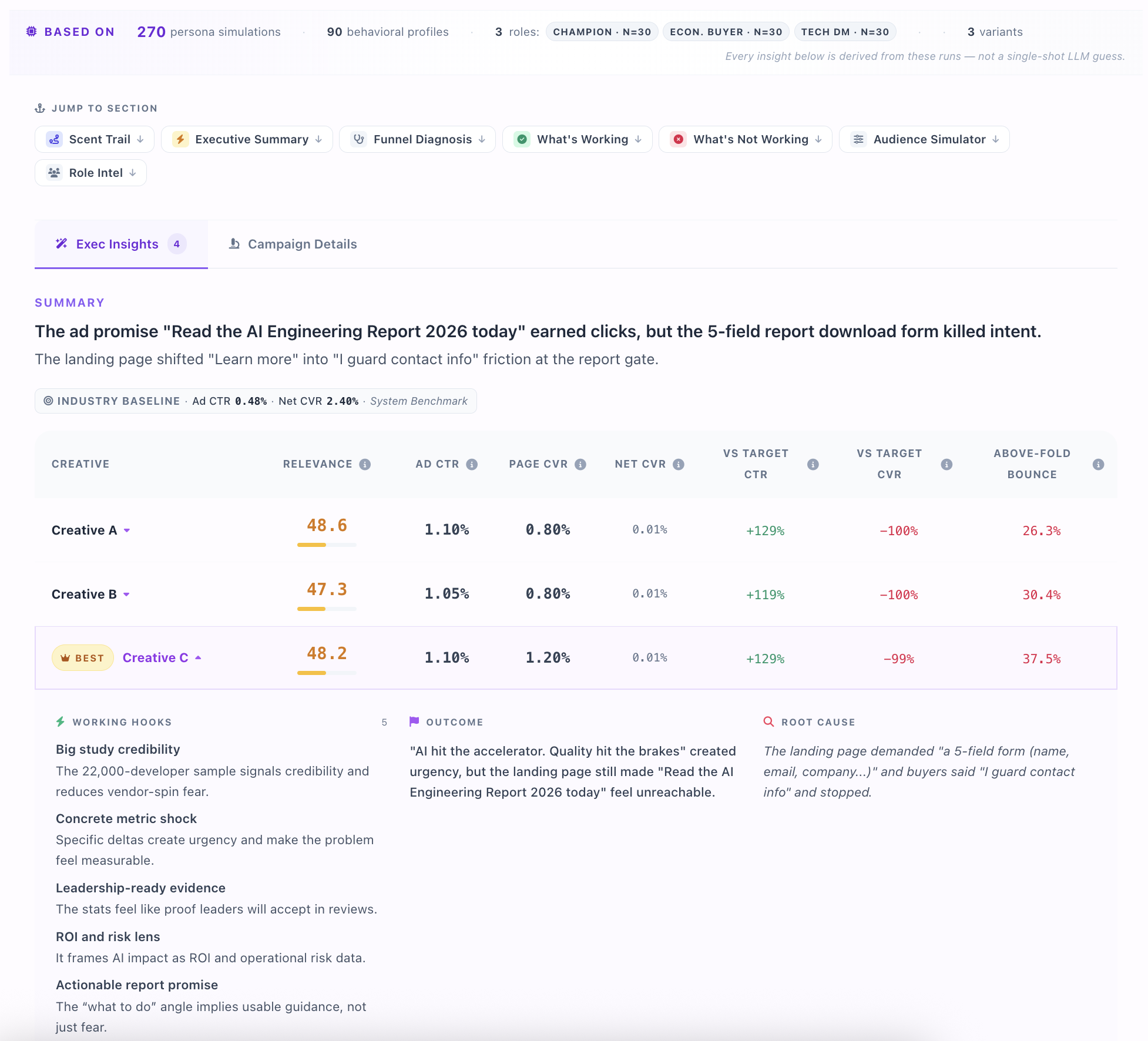
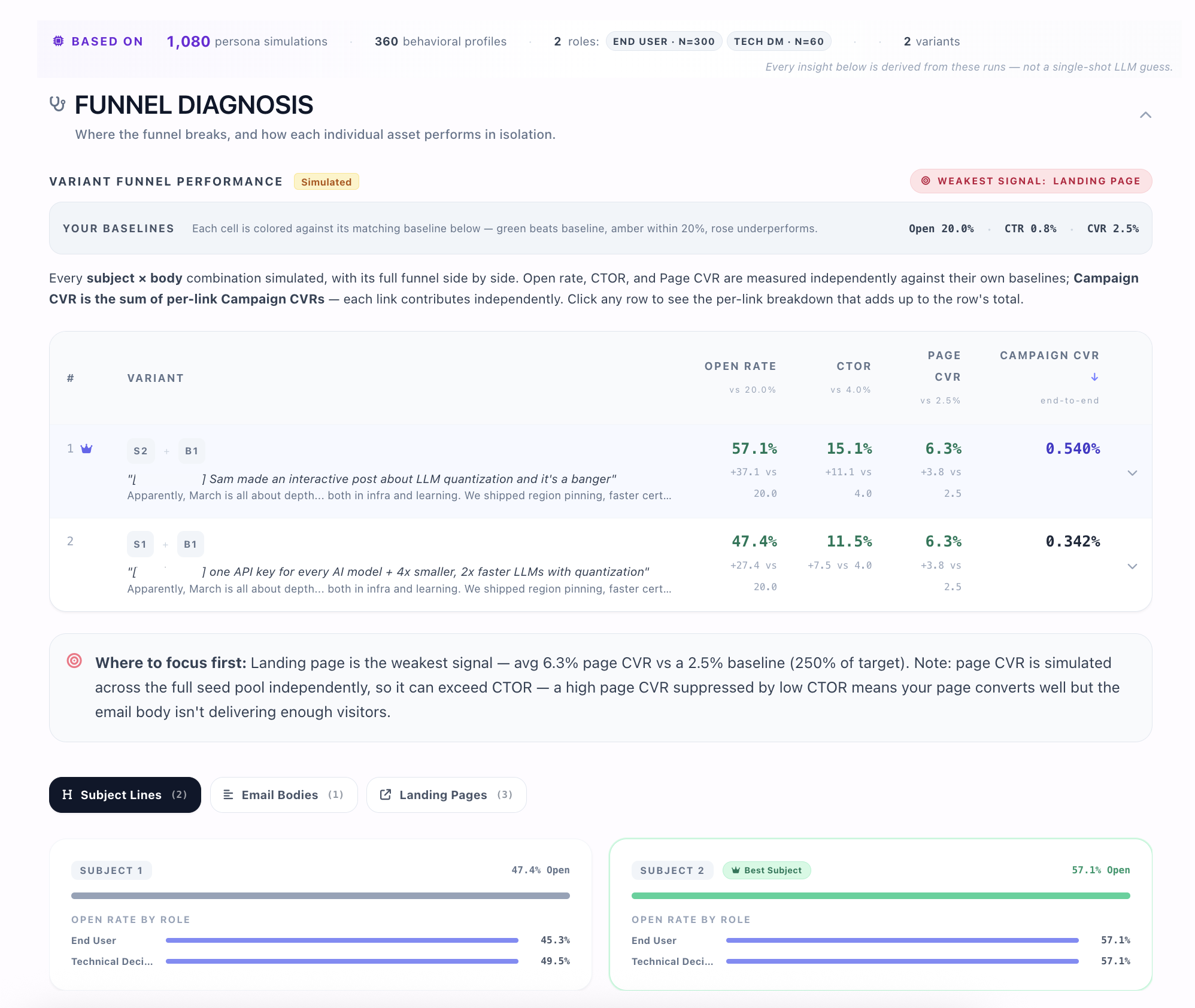
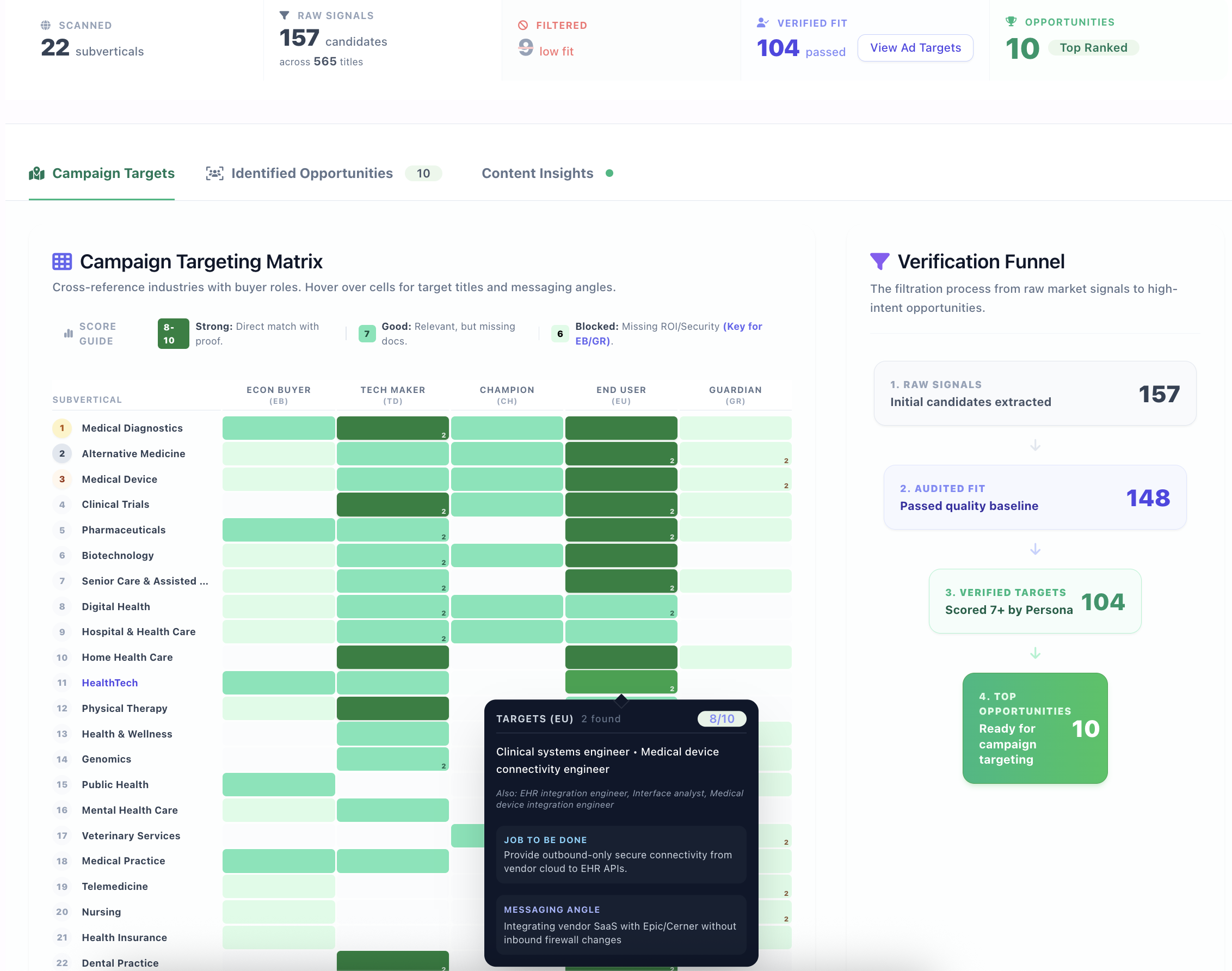
Committee Simulation
Run the page through hundreds of buyer agents, each playing a specific committee role. See who vetoed and what proof was missing.